
Dijkstra算法
系列文章目录:
单源最短路径(1):Dijkstra 算法
单源最短路径(2):Bellman_Ford 算法
单源最短路径(3):SPFA 算法
单源最短路径(4):总结
一:背景
Dijkstra 算法(中文名:迪杰斯特拉算法)是由荷兰计算机科学家 Edsger Wybe Dijkstra 提出。该算法常用于路由算法或者作为其他图算法的一个子模块。举例来说,如果图中的顶点表示城市,而边上的权重表示城市间开车行经的距离,该算法可以用来找到两个城市之间的最短路径。
二:算法过程
我们用一个例子来具体说明迪杰斯特拉算法的流程。
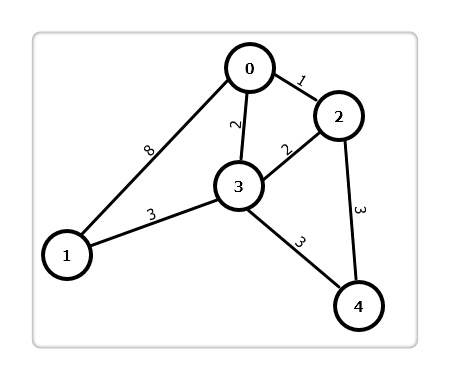
定义源点为 0,dist[i]为源点 0 到顶点 i 的最短路径。其过程描述如下:
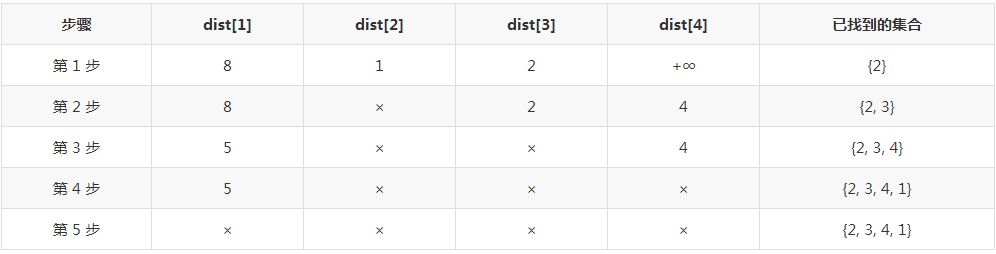
第 1 步:从源点 0 开始,找到与其邻接的点:1,2,3,更新dist[]数组,因 0 不与 4 邻接,故dist[4]为正无穷。在dist[]中找到最小值,其顶点为 2,即此时已找到 0 到 2 的最短路。
第 2 步:从 2 开始,继续更新dist[]数组:2 与 1 不邻接,不更新;2 与 3 邻接,因0→2→3比dist[3]大,故不更新dist[3] ;2 与 4 邻接,因0→2→4比dist[4]小,故更新dist[4]为 4。在dist[]中找到最小值,其顶点为 3,即此时又找到 0 到 3 的最短路。
第 3 步:从 3 开始,继续更新dist[]数组:3 与 1 邻接,因0→3→1比dist[1]小,更新dist[1]为 5;3 与 4 邻接,因0→3→4比dist[4]大,故不更新。在dist[]中找到最小值,其顶点为 4,即此时又找到 0 到 4 的最短路。
第 4 步:从 4 开始,继续更新dist[]数组:4 与 1 不邻接,不更新。在dist[]中找到最小值,其顶点为 1,即此时又找到 0 到 1 的最短路。
第 5 步:所有点都已找到,停止。
对于上述步骤,你可能存在以下的疑问:
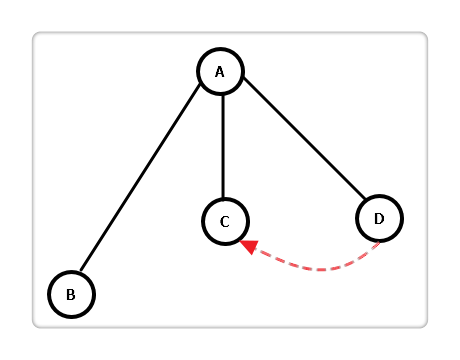
若 A 作为源点,与其邻接的只有 B,C,D 三点,其dist[]最小时顶点为 C,即就可以确定A→C为 A 到 C 的最短路。但是我们存在疑问的是:是否还存在另一条路径使 A 到 C 的距离更小? 用反证法证明。
假设存在如上图的红色虚线路径,使A→D→C的距离更小,那么A→D作为A→D→C的子路径,其距离也比A→C小,这与前面所述 “dist[]最小时顶点为 C” 矛盾,故假设不成立。因此这个疑问不存在。
根据上面的证明,我们可以推断出,Dijkstra 每次循环都可以确定一个顶点的最短路径,故程序需要循环 n-1 次。
三:完整代码
#include <iostream>
#include<cstring>
using namespace std;
int matrix[100][100]; // 邻接矩阵
bool visited[100]; // 标记数组
int dist[100]; // 源点到顶点i的最短距离
int path[100]; // 记录最短路的路径,记录的是与该点直接相连的最短路径
int source; // 源点
int vertex_num; // 顶点数
int edge_num; // 边数
void Dijkstra(int source)
{
memset(visited, 0, sizeof(visited)); // 初始化标记数组,都未被访问
visited[source] = true; //标记源点已被访问
/*更新源点到各点的距离*/
for (int i = 0; i < vertex_num; i++)
{
dist[i] = matrix[source][i];
path[i] = source; //全都初始为源点到该点的距离
}
int min_cost; // 权值最小
int min_cost_index; // 权值最小的下标
for (int i = 1; i < vertex_num; i++) // 整个循环的作用:找到源点到另外 vertex_num-1 个点的最短路径即更新dist数组
{
min_cost = INT_MAX;
for (int j = 0; j < vertex_num; j++) //找到所有相连的权值最小的
{
if (visited[j] == false && dist[j] < min_cost) // 找到权值最小,保证每次从已找到最短路径集团的最小的权值出发
{
min_cost = dist[j];
min_cost_index = j;
}
}
visited[min_cost_index] = true; // 权值最小的点已找到,进行标记
for (int j = 0; j < vertex_num; j++) // 更新 dist 数组
{
if (visited[j] == false &&
matrix[min_cost_index][j] != INT_MAX && // 确保两点之间有边
matrix[min_cost_index][j] + min_cost < dist[j]) //从最小权值出发,找到与该最小权值出发相连的最短路径 matrix[min_cost_index][j]
{
dist[j] = matrix[min_cost_index][j] + min_cost; //更新初始的dist数组 ,即是与上述最小权值出发相连的节点到源点的最短路径
path[j] = min_cost_index; //记录与j点直接相连的最短路径的前一点
}
}
}
}
int main()
{
cout << "请输入图的顶点数(<100):";
cin >> vertex_num;
cout << "请输入图的边数:";
cin >> edge_num;
for (int i = 0; i < vertex_num; i++)
for (int j = 0; j < vertex_num; j++)
matrix[i][j] = (i != j) ? INT_MAX : 0; // 初始化 matrix 数组
cout << "请输入边的信息:\n";
int u, v, w;
for (int i = 0; i < edge_num; i++)
{
cin >> u >> v >> w;
matrix[u][v] = matrix[v][u] = w;
}
cout << "请输入源点(<" << vertex_num << "):";
cin >> source;
Dijkstra(source);
for (int i = 0; i < vertex_num; i++) //通过path数组输出源点到个点的最短 路径
{
if (i != source)
{
cout << source << " 到 " << i << " 的最短距离是:" << dist[i] << ",路径是:" << i;
int t = path[i];
while (t != source)
{
cout << "--" << t;
t = path[t];
}
cout << "--" << source << endl;
}
}
return 0;
}
四:时间复杂度
Dijkstra 算法最简单的实现方法是用一个数组来存储所有顶点的
dist[](即本程序采用的策略),所以搜索dist[]中最小元素的运算需要线性搜索
O(n)。这样的话算法的运行时间是O(n2)。
对于边数远少于O(n2)的稀疏图来说,我们可以用邻接表来更有效的实现该算法,同时需要将一个二叉堆或者斐波纳契堆用作优先队列来查找最小的顶点。当用到二叉堆的时候,算法所需的时间为O((m+n)logn),斐波纳契堆能稍微提高一些性能,让算法运行时间达到O(m+nlogn)。然而,使用斐波纳契堆进行编程,常常会由于算法常数过大而导致速度没有显著提高。
关于O((m+n)logn)的由来,我简单的证明了下:
- 把dist[]数组调整成最小堆,需要O(n)的时间;
- 因为是最小堆,所以每次取出最小值只需O(1)的时间,接着把数组尾的数放置堆顶,并花费O(logn)的时间重新调整成最小堆;
- 我们需要 n-1 次操作才可以找出剩下的 n-1 个点,在这期间,大约需要访问 m 次边,每次访问都可能造成dist[] 的改变,因此还需要O(logn)的时间来进行最小堆的重新调整(从当前dist[]改变的位置往上调整)。
综上所述:总的时间复杂度为:O(n)+O(nlogn)+O(mlogn)=O((m+n)logn)
最后简单说下 Dijkstra 优化时二叉堆的两种实现方式:
- 优先队列,把每个顶点的序号和其dist[]压在一个结构体再放进队列里;
- 自己建一个小顶堆heap[],存储顶点序号,再用一个数组pos[]记录第 i 个顶点在堆中的位置。
相比之下,前者的编码难度较低,因此在平时编程甚至算法竞赛中,都是首选。
五:该算法的缺陷
Dijkstra 算法有个巨大的缺陷,请考虑下面这幅图:
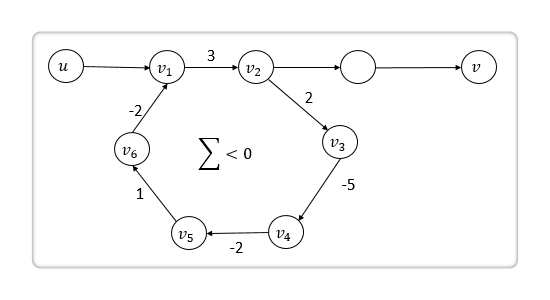
u→v间存在一条负权回路(所谓的负权回路,维基和百科并未收录其名词,但从网上的一致态度来看,其含义为:如果存在一个环(从某个点出发又回到自己的路径),而且这个环上所有权值之和是负数,那这就是一个负权环,也叫负权回路),那么只要无限次地走这条负权回路,便可以无限制地减少它的最短路径权值,这就变相地说明最短路径不存在。一个不存在最短路径的图,Dijkstra 算法无法检测出这个问题,其最后求解的dist[]也是错的。
转载自:https://subetter.com/algorithm/dijkstra-algorithm.html
感谢原作者分享
